- SparkNotes
- Posts
- PART I: What Developers Need to Know About AI Workflows
PART I: What Developers Need to Know About AI Workflows
Shivam Agarwal
October 20, 2025
Today we’re kicking off our three-part series on how AI is transforming renewable energy development. Over the coming weeks, we’ll explore how solar and storage developers can use AI to accelerate diligence, reduce uncertainty, and make faster, evidence-backed decisions.
AI has quickly become one of the most talked-about topics in renewable energy. From site screening to grid modelling, nearly every solar and storage developer is exploring how artificial intelligence can accelerate their workflows. But “AI” isn’t a single technology, it’s a spectrum of very different systems. For developers, the real question isn’t whether to use AI, but which kind of AI can actually move projects forward.

Most development teams today face the same set of bottlenecks: weeks of manual diligence, scattered permitting documents, and constant risk of missing a moratorium or policy change buried deep in a county agenda. In that environment, the temptation to “adopt AI” is understandable. Given the rapid proliferation and accessibility of AI, many companies have a tendency to start with generic tools that aren’t built for regulatory precision. Large language models like ChatGPT are excellent for reasoning, summarizing, and drafting. But when a single missed setback requirement can delay a multimillion-dollar project, a probabilistic model is not enough.
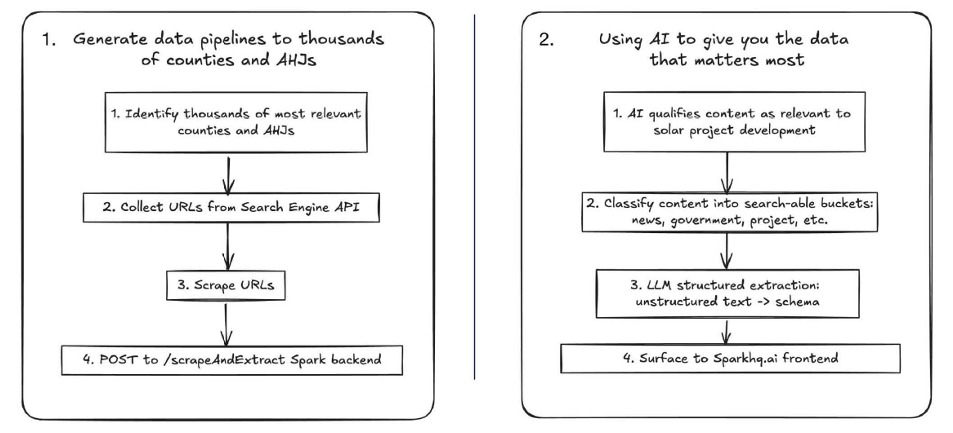
Broadly speaking, there are two categories of AI tools available to developers. The first are general-purpose LLMs, which generate text token by token based on probability. They’re versatile, but their accuracy depends entirely on the user’s prompt and whatever data they can fetch at query time. The second category is domain-specific AI systems, like Spark, which are engineered for deterministic coverage, verifiability, and scale. Spark continuously crawls thousands of authoritative public sources, AHJ websites, meeting minutes, agendas, filings, and local news, normalises that information, extracts key data points such as zoning status and moratoria, and stores each finding with a clear citation and timestamp. The result is structured intelligence that’s both fresh and auditable.
A real AI workflow for renewables doesn’t start with a chatbot; it starts with infrastructure. Spark’s approach follows a deliberate pipeline: crawl → extract → normalize → index → alert → cite. That means a developer can detect a new ordinance before it becomes a headline, track public sentiment shifts around utility-scale solar, or automatically flag changes in county permitting requirements. Every data point is sourced and verifiable, so project teams can make confident decisions backed by evidence.
How Spark AI works
AI is no longer just a research assistant; it’s becoming the backbone of how renewable developers process information and manage risk. For teams building tomorrow’s solar and storage projects, the distinction is simple but essential: large language models help you think, but Spark helps you build.
Stay tuned for Part II, where we’ll dive into how Spark’s Reports feature compares against general-purpose AI tools for market and site screening, and why reproducibility and audibility matter more than ever.